
## Java方向笔试题第一场(单选和不定项)
> 计算类的单选题,就不列出选项。直接改为计算题。
#### 2.求递归方程$T(n)=4T(n/2)+n$ 的解为$O(n^2)$
主定理提供了分治方法带来的递归表达式的渐进复杂度分析.
1.将规模为n的问题通过分治,得到a个规模为n/b的问题,每次递归带来的额外计算为$c(n^d)$
即$T(n)=a(n/b)+c(n^d)$
若 $a=b^d$ , $T(n)=O(n^dlog(n))$
若 $a<b^d$ , $T(n)=O(n^d)$
若$a>b^d$ , $T(n)=O(n^{log_b^a})$
该题 a=4,b=2,d=1。因为a>2,故有 $T(n)=O(n^{log_b^a})=O(n^2)$
#### 3.下列关于动态规划算法说法错误的是(B)
**A.**动态规划关键在于正确地写出基本的递推关系式和恰当的边界条件
**B.**~~当某阶段的状态确定后,当前的状态是对以往决策的总结并且直接影响未来的决策~~
**C.**动态规划算法根据子问题具有重叠性,对每个子问题都只解一次
**D.**动态规划算法将原来具有指数级复杂度的搜索算法改进成具有多项式时间算法
> 动态规划只是说某阶段的最优解状态是对以往状态的总结并且影响未来的的状态,并不是说所有的状态是这样的。
>
> 简单介绍一下,什么是动态规划。动态规划,无非就是利用**历史记录**,来避免我们的重复计算。而这些**历史记录**,我们得需要一些**变量**来保存,一般是用**一维数组**或者**二维数组**来保存。
>
>
>
> 动态规划:
>
> 1.递推关系式.
>
> 2.子问题重叠.
>
> 3.最优子结构.
#### 4.已知图G的邻接表如下图所示,则从V1点出发进行广度优先遍历的序列为( B )

**A.**V1,V2,V3,V4,V5,V6
**B.**V1,V2,V5,V4,V3,V6
**C.**V1,V2,V3,V6,V5,V4
**D.**V1,V2,V4,V6,V5,V3
> **树是图的一种特例(连通无环的图就是树)**
>
>
>
> **广度优先遍历**,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
>
>
>
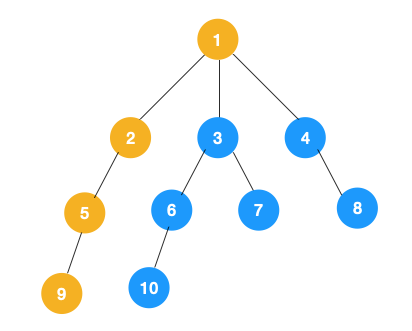
> 上文所述树的广度优先遍历动图如下,每个节点的值即为它们的遍历顺序。所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。
>
>
>
> 
> 深度优先遍历:指的是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底...,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
>
>
>
> 
>
>
>
> 解决本道题,先通过图G的邻接表,把图G当做一棵特殊的树进行处理,反向推演出这棵树的树形结构。然后进行还是进行深度优先遍历,得出序列。
>
> 或者这么处理,换一个方法。
>
>
>
> 广度优先遍历用到**队列**知识点。
>
> 从v1开始,v1先进队列:
>
> 
>
> 然后访问v1,v1出队列,v1邻接点v2、v5、v4进队列:
>
> 
>
> 然后按队列里顺序访问v2,v2出队列,v2临邻接点v3、v5进队列,v5已经在队列里,只进v3。
>
> 
>
> 然后访问v5,v5出,v6进队列。
>
> 
>
> ...
>
> 以此类推,得广度优先搜索遍历序列:v1 v2 v5 v4 v3 v6
#### 5.以下哪个不是队列的应用( D )
**A.**图的广度优先搜索
**B.**设置打印数据缓冲区
**C.**树的层次遍历
**D.**中缀表达式转后缀表达式
> 后缀表达式也叫逆波兰式,中缀表达式转后缀表达式是利用栈Stack实现的。因此选D.
>
>
>
> 来分析其余选项,在上面的第4道题就涉及到队列的应用,图的广度优先搜索与树的层次遍历(树的广度优先遍历)就刚刚在上题涉及到。
>
>
>
> 那么设置打印数据缓冲区就很好利用队列的特性。威力解决计算机主机与打印机之间速度不匹配问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,打印机则从该缓冲区中取出数据打印,该缓冲区
#### 6.有如图所示的二叉树,其后序遍历的序列为( B )

**A.**ABDGCEHF
**B.**BGDAEHCF
**C.**GDBHEFCA
**D.**ACFEHBDG
> 
>
>
>
> 前序遍历:根节点->左子树->右子树**(根->左->右)**
>
> 中序遍历:左子树->根节点->右子树**(左->根->右)**
>
> 后序遍历:左子树->右子树->根节点**(左->右->根)**
#### 7.折半查找法对带查找列表的要求为( B )
**A.**必须采用链式存储结构、必须按关键字大小有序排列
**B.**必须采用顺序存储结构、必须按关键字大小有序排列
**C.**必须采用链式存储结构、必须没有数值相等的元素
**D.**必须采用链式存储结构、必须有数值相等的元素
> 折半查找法又称为二分查找法,这种方法对待查找的列表有两个要求:
> (1)必须采用顺序存储结构
> (2)必须按关键字大小有序排列
>
>
>
> 算法思想
> 首先,将表的中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则查找前一子表,否则查找后一子表。
> 重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
#### 8.一组N个站点共享一个30Kbps的纯ALOHA信道, 每个站点平均每100s输出一个2000bit的帧。试求出N的最大值( B )
**A.**1030
**B.**276
**C.**1500
**D.**1200
> 首先ALOHA信道的最高利用率为18.4%,那么30kbps x 0.184 =5.52kbps 2000bit÷100s=20bps,N=5520bps÷20bps=276
#### 9.在Linux系统中,某文件权限的分数是754,则以下说法错误的是( B )
**A.**拥有者的权限是可读、可写、可执行
**B.**~~同用户组的权限是可写可执行~~ 5=4+1,r+e,可读可执行
**C.**其他用户权限只有可读
**D.**所有用户对该文件都可读
> 3个数字对应3种用户的权限:文件所有者、同组用户、其他用户
>
> 在linux中
>
> r(read) 权限数值为4 w(wtite) 权限数值为2 e(execute) 权限数值为1
>
> 7表示4+2+1 即可读可写可执行 为文件所有者权限
>
> 5表示4+1 即可读可执行 为同组用户权限
>
> 4表示4 即可读 为其他用户权限
#### 10.有一张表,列名称和列类型如下:
```sql
Id Int unsigned
Uname Varchar(30)
gender Char(1)
weight Tinyint unsigned
Birth Date
Salary Decimal(10,2)
lastlogin Datetime
info Varchar(2000)
```
对这张表进行优化,可行的是( **BCD** )
**A.**不用优化
**B.**将Id列设置为主键
**C.**为了提高查询速度,让变长的列定长
**D.**Info列放在单独的一张表中
> 将Id列设置为主键(增加索引);
>
> 为了提高查询速度,让变长的列定长;
>
> Info列放在单独的一张表中(优化数据库存储性能)
>
>
#### 11.在Java线程中可以通过setDaemon(true);设置线程为守护线程,可以使用join()合并线程。如何正确使用两个方法(A)
**A.**在启动线程start()前使用setDaemon(true);
**B.**在启动线程start()前使用join();
**C.**在启动线程start()后使用setDaemon(true);
**D.**两个方法都要放在start()方法之前调用
> 在启动线程start()前使用setDaemon(true);
>
> thread = new Thread(this);
>
> thread.setDaemon(true);
>
> thread.start();
>
> t.join方法是将当前线程加入t的wait队列,等到t执行完成再唤醒当前线程。
**附讲解资料:**
Java分为两种线程:用户线程和守护线程
当我们在Java中创建一个线程,缺省状态下它是一个User线程,如果该线程运行,JVM不会终结该程序。当一个线被标记为守护线程,JVM不会等待其结束,只要所有用户(User)线程都结束,JVM将终结程序及相关联的守护线程。Java中可以用 Thread.setDaemon(true) 来创建一个守护线程。咱们看一个Java中有关守护线程的例子。如果我们不将一个线程以守护线程方式来运行,即使主线程已经执行完毕,程序也永远不会结束,可以尝试把上述将线程设为守护线程的那句注释掉,重新运行看看结果:通常我们创建一个守护线程,对于一个系统来说在功能上不是主要的。例如抓取系统资源明细和运行状态的日志线程或者监控线程。
```java
public class JavaDaemonThread {
public static void main(String[] args) throws InterruptedException {
Thread dt = new Thread(new DaemonThread(), "dt");
dt.setDaemon(true);//译者注:此次将User线程变为Daemon线程
//在启动线程start()前,使用setDaemon(true)
dt.start();
//continue program
Thread.sleep(30000);
System.out.println("Finishing program");
}
}
class DaemonThread implements Runnable{//译者注:此类虽类名是为Daemon线程,其实为User线程
@Override
public void run() {
while(true){
processSomething();
}
}
private void processSomething() {
try {
System.out.println("Processing daemon thread");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
```
```
当你运行该程序,JVM 在main()方法中先创建一个用户线程,再创建一个守护线程。当main()方法结束后,程序终结,同时JVM也关闭守护线程。
下面就是上述程序执行的结果:
Processing daemon thread
Processing daemon thread
Processing daemon thread
Processing daemon thread
Processing daemon thread
Processing daemon thread
Finishing program
```
#### 12.对于如下代码,描述正确的是: (BD)
```java
class Animal{
public void move(){
System.out.println("the animal is moving");
}
}
class Dog extends Animal{
public void move(){
System.out.println("the dog can run");
}
public void bark(){
System.out.println("the dog can bark");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal();
Animal b = new Dog();
}
}
```
**A.**a 对象可以调用move方法,输出为:the dog can run
**B.**a 对象可以调用move方法,输出为:the animal is moving
**C.**b对象可以调用bark方法输出为:the dog can bark
**D.**b 对象不能调用bark方法。
> a 对象可以调用move方法,输出为:the animal is moving
>
> b 对象不能调用bark方法。(需要((Dog)b).bark())
#### 13.对于如下代码,运行结果是:(A)
```java
public class Test {
public static void main(String[] args) {
double[] nums = {-1.6};
for (double num : nums) {
test(num);
}
}
private static void test(double num) {
System.out.println(Math.floor(num));
System.out.println(Math.ceil(num));
}
}
```
**A.**
```
'-2.0
-1.0
```
**B.**
```
'-1.0
-2.0
```
**C.**
```
'-2
-1
```
**D.**
```
'2
1
```
> Math.floor向下取整 Math.ceil向上取整 且为double类型小数点依然存在。
#### 14.阅读下列代码
```java
import java.util.Arrays;
public class Test
{
public static void main(String [] args)
{
int a[] ={34,12,35,54,22,33,56};
Arrays.sort(a);
for(int j=0;j<a.length;j++)
System.out.print(a[j]+"");
}
}
```
输出结果正确的是 (**A**)
**A.**12 22 33 34 35 54 56
**B.**22 33 34 35 54 12 56
**C.**56 54 35 34 33 22 12
**D.**33 34 35 54 12 56 22
> Arrays.sort()默认为升序排序
#### 15.一个函数定义如下:
```java
public void doSomething( int[][] mat)
{
for( int row = 0; row < mat.length; row++)
for(int col = 0; col < mat[0].length; col++)
mat[row][col] = mat[row][mat[0].length - 1 - col];
}
```
如果mat为下列2行6列的值:
```
1 3 5 7 9 11
0 2 4 6 8 10
```
那么,doSomething(mat)执行完成后,mat的值是?()
**A.**
```
11 9 7 7 9 11
10 8 6 6 8 10
```
**B.**
```
1 3 5 5 3 1
0 2 4 4 2 0
```
**C.**
```
11 9 7 5 3 1
10 8 6 4 2 0
```
**D.**
```
1 3 5 7 9 11
1 3 5 7 9 11
```
> 千万不要忘记前面的已经修改过了
> 如mat[0][0]=mat[0][5](11),mat[0][5]=mat[0][0](11)
#### 16.
```
public class Test {
private int eat=1;
double drink = 2.0;
protected int sleep = 3;
public double run = 4.0;
}
```
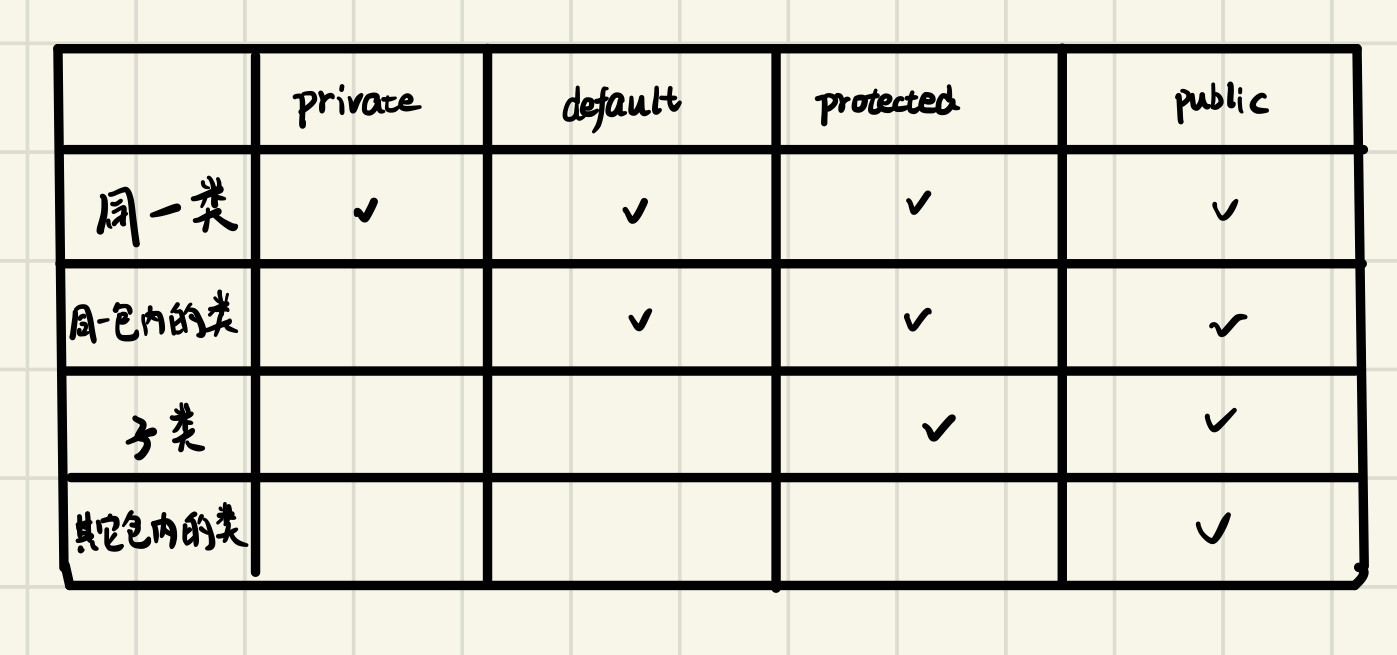
与Test在同一个包下的子类对象可以访问以下哪些变量(**BCD**)
**A.**eat
**B.**drink
**C.**sleep
**D.**run
> 
#### 17.下面关于异常的描述正确的是(ABD)
**A.**Throwable是所有异常的根
**B.**所有异常都是在运行后报错
**C.**异常分为Error和Exception
**D.**有一部分异常编译器会程序员检查并处理
> 所有异常类都是从java.lang.Exception类继承的子类,而Exception类又是Throwable类的子类,Throwable类除Exception之外,还有个子类Error.
#### 18.关于多线程,以下说法正确的是()
**A.**并发和并行都用到了多线程
**B.**要实现多线程只可以通过继承Thread类
**C.**synchronized关键字是为了解决共享资源竞争的问题
**D.**在java中,每个对象可以获得多个同步锁
> 并发: 在某一时刻只能执行一个进程,在一段时间中多个进程轮换执行,宏观上这段时间内有多个进程一起执行。
> 并行: 在某一时刻可以多个进程一起执行。
>
> Java中线程的创建有两种方式:
> 1. 通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中
> 2. 通过实现Runnable接口,实例化Thread类
#### 19.下面关于创建型模式说法错误的是( )
**A.**适配器模式属于结构型模式
**B.**创建型模式关注的是功能的实现
**C.**当我们想创建一个具体的对象而又不希望指定具体的类时可以使用创建型模式
**D.**创建者模式是一个对对象的构建过程“精细化”的构建过程,每个部分的构建可能是变化的,但是对象的组织过程是固定的
> 创建型模式共有5种,分别如下:
>
> - 简单工程模式
> - 工厂方法模式
> - 抽象工厂模式
> - 建造者模式
> - 单例模式
>
>
>
> 创建型模式(Creational Pattern)对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离。为了使软件的结构更加清晰,外界对于这些对象只需要知道它们共同的接口,而不清楚其具体的实现细节,使整个系统的设计更加符合单一职责原则。
>
>
>
> 创建型模式在创建什么(What),由谁创建(Who),何时创建(When)等方面都为软件设计者提供了尽可能大的灵活性。创建型模式隐藏了类的实例的创建细节,通过隐藏对象如何被创建和组合在一起达到使整个系统独立的目的。
#### 20.在顺序图中,如下图形表示的是( A )

**A.**激活的对象
**B.**带有生命线的对象
**C.**未激活的对象
**D.**注释体

IQIYI--Java方向笔试题第一场(单选和不定项)
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可
Links: /archives/iqiyi--java-fang-xiang-bi-shi-ti-di-yi-chang--dan-xuan-he-bu-ding-xiang-


